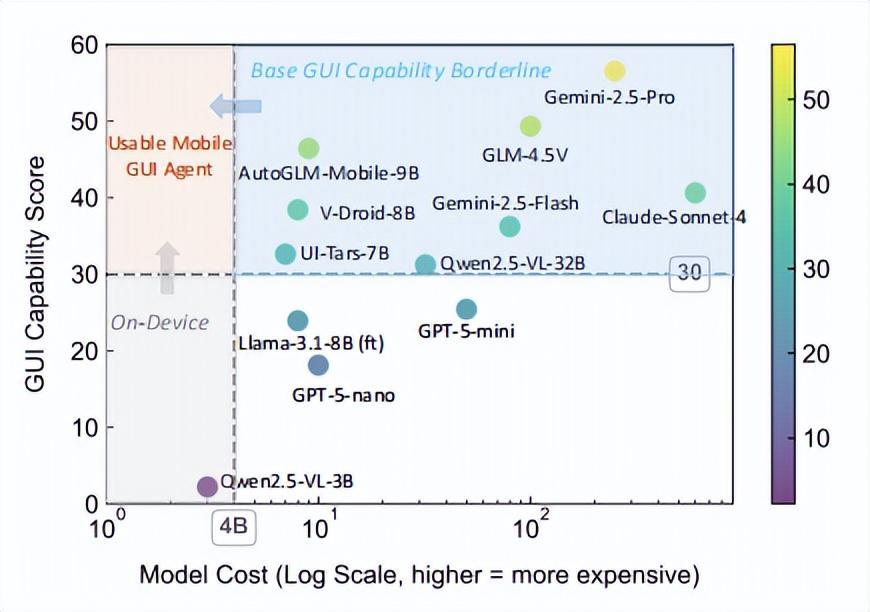
深度强化学习的物理极限突破:Swift无人机竞速的技术解析与应用启示
在瑞士苏黎世的实验室里,一架名为Swift的无人机正在以每小时百公里的速度掠过七个方形赛道门。这不仅仅是一场竞速比赛,更是深度强化学习在物理世界中实现的一次里程碑式跨越。当人类顶尖选手在高清图传中寻找最佳入弯角度时,Swift正通过机载传感器捕捉高维视觉与惯性信息,将数十毫秒的决策过程压缩至极致。这场比赛的核心价值在于,它验证了AI在实时、高动态物理环境下的决策与控制能力,打破了以往AI仅局限于虚拟棋盘或受控实验室环境的认知。
Swift的成功并非偶然,而是基于一套严谨的系统架构。其核心分为感知与控制两大模块。感知系统采用了视觉惯性里程计(VIO)技术,将高维的图像流转化为低维的运动指令,这种处理机制极大地降低了系统延迟。控制策略则基于On-policy深度强化学习,通过数以万计的模拟训练,让AI在虚拟环境中习得了复杂机动动作。为了弥合模拟器与物理世界之间的鸿沟,研究团队引入了MLP残差模型,利用真实数据对感知偏差进行实时校准,确保了控制指令的精准度。
从比赛数据分析来看,Swift展现出了机器特有的稳定性。在数百圈的测试中,AI不仅保持了更高的平均速度,且圈速方差极小,这意味着它能够始终保持在最优轨迹上。相比之下,人类选手在领先时倾向于采取保守策略以降低碰撞风险,这体现了人类基于经验的风险管理逻辑。而AI的短板在于其适应性,一旦光照环境改变或发生意外碰撞,缺乏恢复训练的系统便显得脆弱。这一对比揭示了当前AI在处理突发状况时的局限性,即缺乏类似人类的“直觉”与容错能力。
工程落地中的关键技术挑战
将深度学习模型部署至物理系统,最核心的难点在于感知延迟与环境适应性。在高速竞速场景下,任何微小的感知误差都会被放大为严重的轨迹偏移,因此,如何优化VIO模块与神经网络的协同处理效率,成为决定系统上限的关键。目前,Swift通过将传感器延迟控制在40毫秒以内,成功超越了人类的平均反应速度,这一技术路径为自动驾驶及工业机器人提供了宝贵的参考范式。
除了感知优化,环境的泛化能力也是制约AI走出实验室的重要因素。Swift在面对光照变化时的表现暴露出当前强化学习模型对特定环境的过度拟合,这要求未来的研究必须引入更具鲁棒性的数据增强技术。通过在训练过程中模拟更多不确定性因素,可以有效提升模型在复杂动态环境下的稳定性,从而推动AI技术在无人机物流、灾害救援等领域实现更深度的应用。
最后,物理系统中的数据闭环建设至关重要。Swift通过采集物理系统数据来驱动残差模型,这种“模拟训练+物理校准”的混合模式,是解决Sim-to-Real(模拟到真实)鸿沟的有效手段。对于企业而言,这意味着在开发自主移动机器人时,不能仅依赖于单一的训练环境,必须构建一套从感知、控制到反馈的完整数据链路,才能确保AI在复杂现实世界中具备真正的执行力。